
🌱 오늘의 주제 : Database - INDEX란?
🌱 Database - INDEX란?
- 데이터를 빠르게 조회하기 위한 Key 개념
- WHERE 절에서 자주 조회되는 컬럼을 index로 등록하면 조회가 빨라진다.
- 특정 컬럼 또는 여러 컬럼을 묶어 INDEX로 등록할 수 있다.
- 여러 컬럼을 묶은 INDEX: 복합 INDEX 또는 복합키
- 데이터가 insert 될 때, 인덱스 데이터도 따로 저장 된다.(인덱스가 너무 많으면 입력 속도 느려지고 용량 차지)
🌱 InnoDB의 인덱스 구조
MySQL의 스토리지 엔진인 InnoDB의 경우 B+Tree 자료구조로 구성되어 있다.(B-Tree의 확장 개념)
- 균형 트리
- 복잡도: O(LogN)
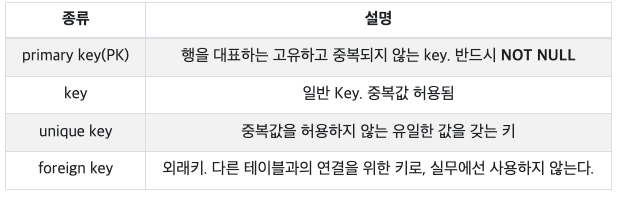
🌱 INDEX의 종류
🌱 인덱스는 언제 사용하는가?
- WHERE절에서 조회 조건이 빈번히 일어날 때
- NULL 값이 많은 데이터들 중 NULL이 아닌 데이터를 찾을 때 유용
- 특정 컬럼을 기준으로 데이터를 정렬할 때 index를 사용하는 것이 좋다.
🌱 테이블 생성하면서 INDEX 추가하기
-- 테이블 생성하며 인덱스 등록하기
CREATE TABLE `student` (
`id` int NOT NULL AUTO_INCREMENT,
`name` char(4) NOT NULL,
`address` varchar(50) NOT NULL,
`department` enum('국문과','영문과','컴퓨터공학과','전자공학과','물리학과') NOT NULL,
`introduction` text NOT NULL,
`studentId` char(255) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_studentId` (`studentId`) USING BTREE,
KEY `idx_department` (`department`),
KEY `idx_department_address` (`department`, `address`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
drop table `student`;
-- 테이블 생성과 인덱스 등록 따로하기
CREATE TABLE `student` (
`id` int NOT NULL AUTO_INCREMENT primary key,
`name` char(4) NOT NULL,
`address` varchar(50) NOT NULL,
`department` enum('국문과','영문과','컴퓨터공학과','전자공학과','물리학과') NOT NULL,
`introduction` text NOT NULL,
`studentId` char(255) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- UNIQUE KEY 추가: number 컬럼에는 중복값이 들어갈 수 없다.
ALTER TABLE `student` ADD UNIQUE INDEX `index_studentId` (`studentId`) USING BTREE;
-- 일반 인덱스 추가
ALTER TABLE `student` ADD INDEX `idx_department` (`department`);
-- 일반 복합 인덱스 추가
ALTER TABLE `student` ADD INDEX `idx_department_address` (`department`, `address`);
🌱 실행 계획(성능) 보기
MySQL의 옵티마이저가 어떻게 판단해서 쿼리를 실행하는지 정보를 본다.
- 인덱스가 여러개인 경우 하나만 선택된다.
explain 쿼리문;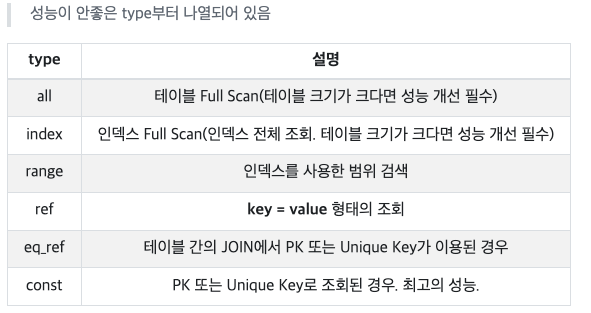
select * from customer;
-- index가 없는 컬럼 like: 인덱스가 없으므로 full scan
explain select * from customer where first_name like 'A%';
explain select * from customer where first_name like '%A';
explain select * from customer where first_name like '%A%';
-- index가 있는 컬럼 like
explain select * from customer where last_name like 'A%'; -- range scan
explain select * from customer where last_name like '%A'; -- full scan
explain select * from customer where last_name like '%A%'; -- full scan
-- pk로 값 조회: const
explain select * from customer where customer_id = 3;
-- index 없는 컬럼 값 조회: full scan
explain select * from film where length = 100;
-- index로 값 조회: ref
explain select * from customer where store_id = 2;
-- pk로 범위 조회
explain select * from film where film_id < 10; -- range
explain select * from film where film_id < 1000; -- range
-- index가 없는 컬럼 범위 조회
explain select * from film where length < 50; -- full scan
-- length 컬럼 index 추가하기
alter table film add index `idx_length` (`length`);
-- index로 범위 조회
explain select * from film where length < 50; -- range
explain select * from film where length < 100; -- full scan --> 데이터 수가 적기 때문에 옵티마이저가 풀스캔이 낫다고 판단
-- index 삭제하기
alter table film drop index `idx_length`;
🌱 인덱스 사용시 주의할 점
- 인덱스가 여러개일 경우, 의도한 인덱스를 타지 않을 수 있으므로 실행 계획을 확인할 것
- 카디널리티(Cardinality)가 낮으면 사용하지 않는다.(중복도가 높은 경우)
- 예) 성별 컬럼 - 남성이 80% 여성이 20%인 경우 INDEX 효과 없음
- 예) 과목 컬럼 - 국어, 영어, 수학. 세 과목만 존재하는데 데이터가 많은 경우
- 컬럼의 값의 갱신이 자주 일어나는 경우 사용하지 않는다.
- WHERE 구문과 ORDER BY에서의 컬럼이 다른 경우 한쪽 index가 선택되므로 실행 계획 확인할 것
'Database' 카테고리의 다른 글
| Database - Query (MySQL) (0) | 2023.03.13 |
|---|---|
| Database - MySQL Workbench 프로그램 사용법 (0) | 2023.03.13 |
| Database - 테이블 생성/삭제/수정 (MySQL) (0) | 2023.03.13 |
| Database - 테이블 설계 (0) | 2023.02.21 |
| Database - 데이터베이스란? (0) | 2023.02.20 |