
▶현재 시간 : 2022년 10월 18일 14:10 P.M.
▶웹스크래핑(크롤링) 기초
- 웹스크래핑(크롤링)이란?
크롤링(crawling) 혹은 스크레이핑(scraping)은 웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위다. 크롤링하는 소프트웨어는 크롤러(crawler)라고 부른다.
검색 엔진에서도 유사한 것을 필수적으로 사용하는데, 웹 상의 다양한 정보를 자동으로 검색하고 색인하기 위해 사용한다. 이때는 스파이더(spider), 봇(bot), 지능 에이전트라고도 한다. 사람들이 일일이 해당 사이트의 정보를 검색하는 것이 아니라 컴퓨터 프로그램의 미리 입력된 방식에 따라 끊임없이 새로운 웹 페이지를 찾아 종합하고, 찾은 결과를 이용해 또 새로운 정보를 찾아 색인을 추가하는 작업을 반복 수행한다. 방대한 자료를 검색하는 특징은 있으나 로봇의 검색 기능을 역이용하여 순위를 조작하거나 검색을 피할 수 있는 단점도 있다. 네이버, 구글 등도 이런 봇을 이용해 운영된다.
- 관련 소프트웨어
Python이 이 분야의 선두주자로서, 컴퓨터 프로그래밍이 익숙하지 않은 비전공자들인 인문학이나 통계 분야의 종사자들이 쓰기 쉽도록 라이브러리들이 발달하면서 급격히 발전하고 있다. 대표적인 파이썬 라이브러리의 예로 beautifulsoup[1]등이 있다.
그외에도 selenium이라는 라이브러리가 인기를 끌고있다. webdriver와 headless 옵션을 함께 이용해서 웹을 자동화 시킬수도 있다.
Java에도 jsoup이라는 HTML 파싱 라이브러리가 존재한다. 파이썬의 beautifulsoup처럼 특정 조건을 가진 태그들을 선택하는 것이 가능하며, GET/POST 요청을 보내서 응답을 받아오는 것도 가능하다.
전문적인 크롤링 소프트웨어는 아니지만, 일반인들이 사용할 만한 툴로는 httrack과 wget-curl 정도가 있다. 인터넷이 느렸던 2000년대 초반에는 WebZip이라는 것이 인기를 모으기도 하였다.
그외에도 selenium이라는 라이브러리가 인기를 끌고있다. webdriver와 headless 옵션을 함께 이용해서 웹을 자동화 시킬수도 있다.
Java에도 jsoup이라는 HTML 파싱 라이브러리가 존재한다. 파이썬의 beautifulsoup처럼 특정 조건을 가진 태그들을 선택하는 것이 가능하며, GET/POST 요청을 보내서 응답을 받아오는 것도 가능하다.
전문적인 크롤링 소프트웨어는 아니지만, 일반인들이 사용할 만한 툴로는 httrack과 wget-curl 정도가 있다. 인터넷이 느렸던 2000년대 초반에는 WebZip이라는 것이 인기를 모으기도 하였다.
▶웹스크래핑 해보기 (영화 제목)
- 네이버영화 페이지 스크래핑 하기
https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829- 패키지 추가 설치하기(beautifulsoup4)
bs4
- 크롤링 기본 세팅
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')
#############################
# (입맛에 맞게 코딩)
#############################
- select / select_one의 사용법 익히기
태그 안의 텍스트를 찍고 싶을 땐 → 태그.text
태그 안의 속성을 찍고 싶을 땐 → 태그['속성']
import requests
from bs4 import BeautifulSoup
# URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
# a의 text를 찍어본다.
print (a_tag.text)
- beautifulsoup - select에 미리 정의된 다른 방법
# 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')
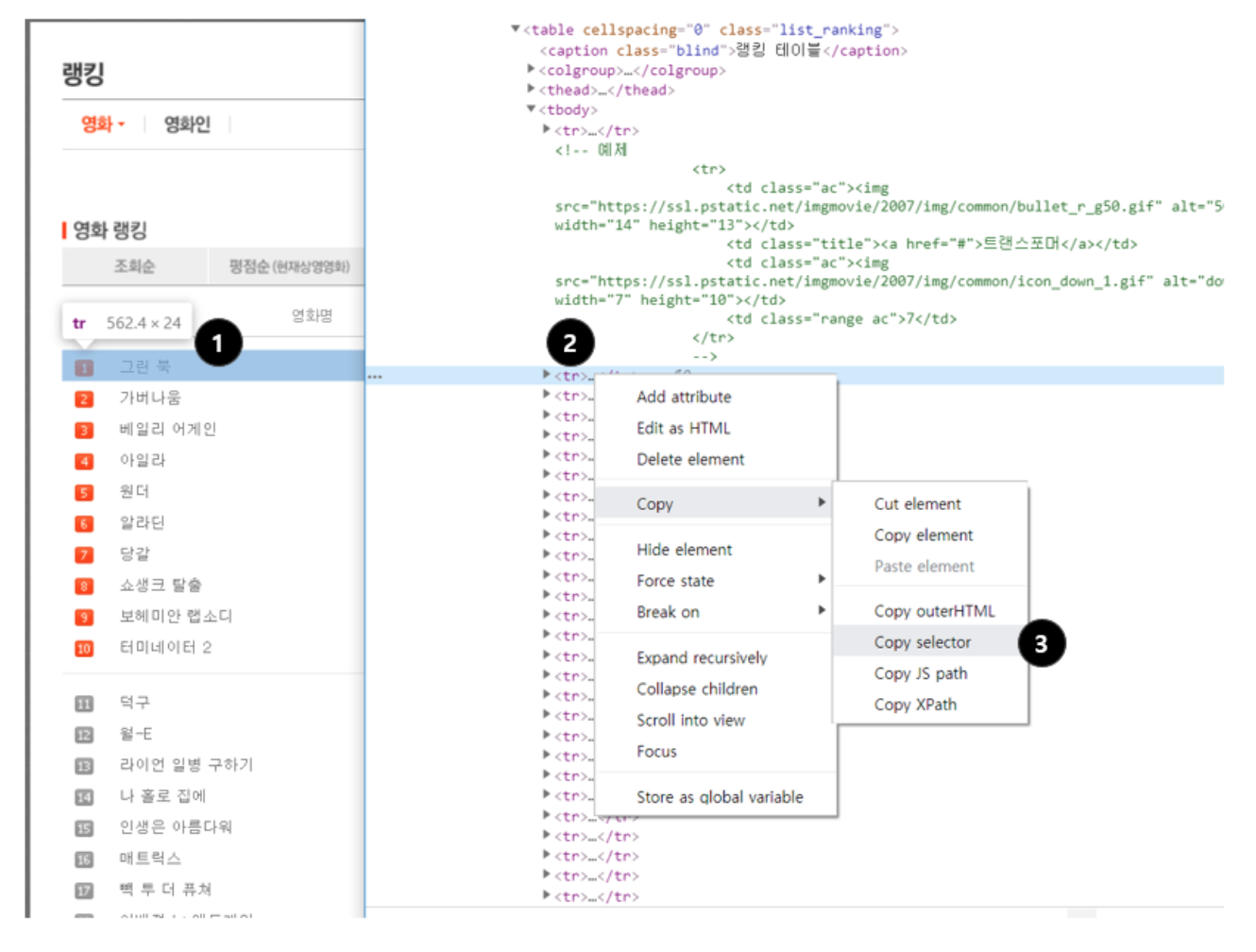
- 항상 정확하지는 않으나, 크롬 개발자도구를 참고 가능.
- 원하는 부분에서 마우스 오른쪽 클릭 → 검사
- 원하는 태그에서 마우스 오른쪽 클릭
- Copy → Copy selector로 선택자를 복사할 수 있음
▶웹스크래핑(크롤링) 연습
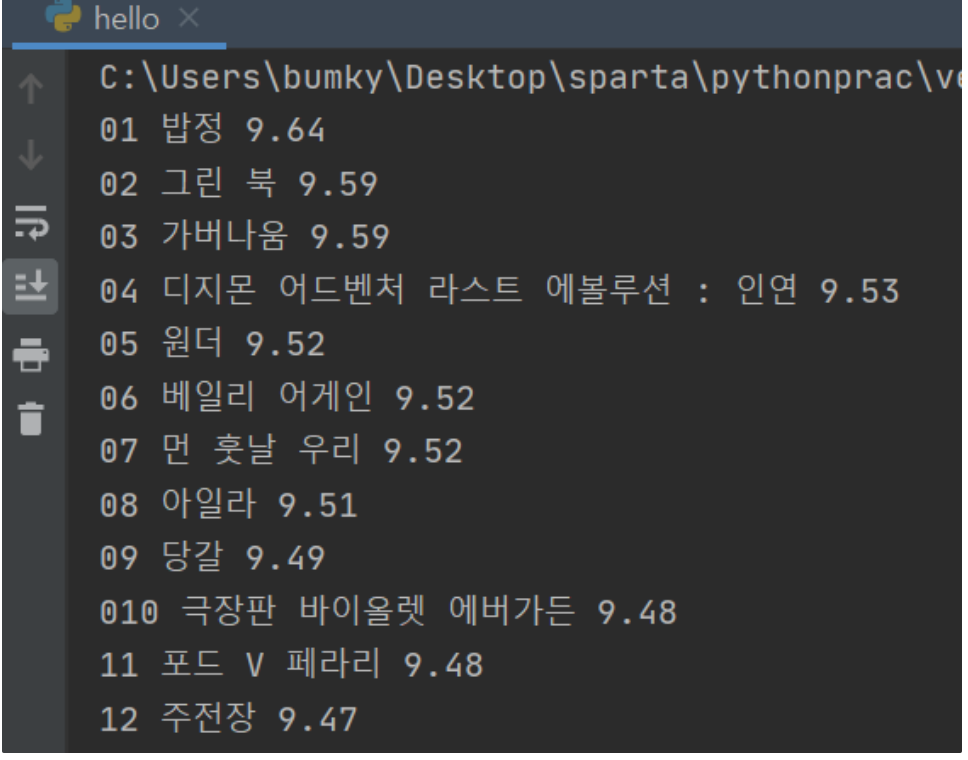
- 웹스크래핑 해보기 (순위, 제목, 별점)
- 완성 코드
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb+srv://test:sparta@cluster0.oqyeqew.mongodb.net/Cluster0?retryWrites=true&w=majority', tlsCAFile=ca)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
title = a.text
rank = movie.select_one('td:nth-child(1) > img')['alt']
star = movie.select_one('td.point').text
print(rank,title,star)
doc = {
'title': title,
'rank': rank,
'star': star
}
db.movies.insert_one(doc)
'Web development (3)' 카테고리의 다른 글
| 웹개발 3주차 (5) - 웹스크래핑(크롤링) 연습 (0) | 2022.10.18 |
|---|---|
| 웹개발 3주차 (4) - DB (0) | 2022.10.18 |
| 웹개발 3주차 (2) - requests (0) | 2022.10.18 |
| 웹개발 3주차 (1) - Python기초 문법 (0) | 2022.10.18 |