Web development (4)
웹개발 4주차 (3) - Flask 연습 (meta 태그, 스파르타피디아 프로젝트)
요가하는 개발자
2022. 10. 20. 14:46
▶현재 시간 : 2022년 10월 20일 2:20 P.M.
flask 이해하기 위해 연습 또 연습!
▶프로젝트 준비
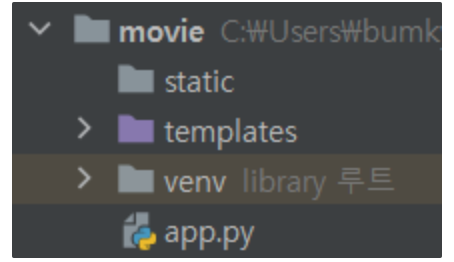
- flask 폴더 구조 만들기
static, templates 폴더 + app.py 만들기! 이젠 너무 익숙하죠?
- 패키지 설치하기
5개 : flask, pymongo, dnspython, bs4, requests
▶[스파르타피디아] - 조각 기능 구현해보기
- 프로젝트 준비 - URL에서 페이지 정보 가져오기 (meta태그 스크래핑)
어떤 부분에 스크래핑이 필요한가요? -우리는 URL만 입력했는데, 자동으로 불러와지는 부분들이 있습니다. 바로 '제목', '썸네일 이미지', '내용' 입니다. 이 부분은, 'meta'태그를 크롤링 함으로써 공통적으로 얻을 수 있습니다. meta태그가 무엇이고, 어떻게 스크래핑 하는지, 함께 살펴볼까요?
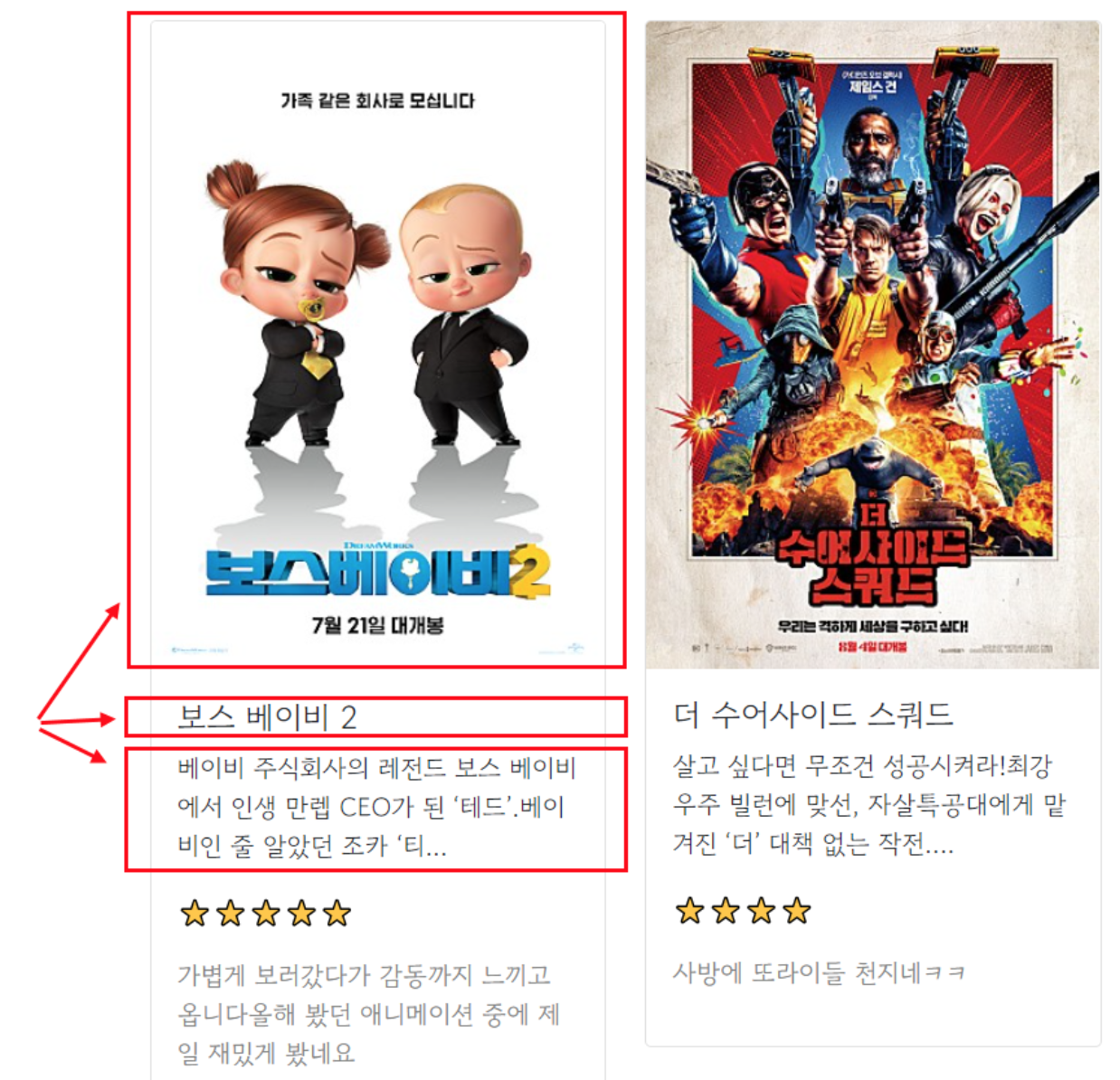
- meta 태그에 대해 알아보기
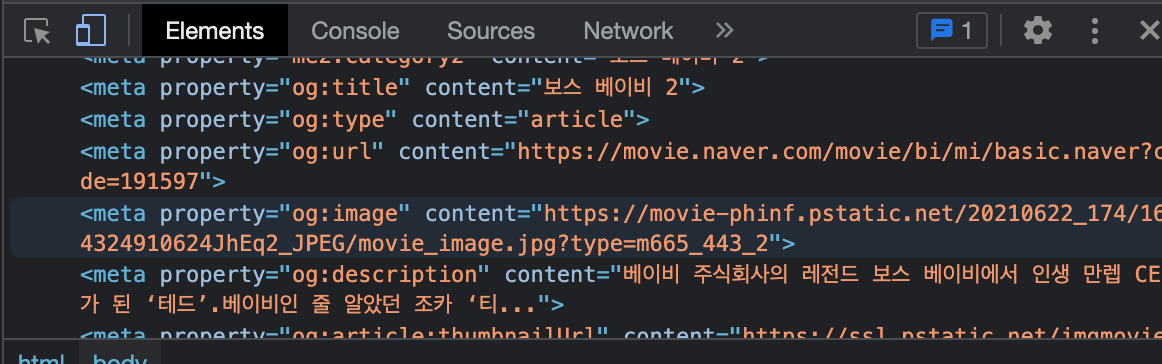
https://movie.naver.com/movie/bi/mi/basic.naver?code=191597 에 접속한 뒤 크롬 개발자 도구를 이용해 HTML의 생김새를 살펴볼까요?
메타 태그는, <head></head> 부분에 들어가는, 눈으로 보이는 것(body) 외에 사이트의 속성을 설명해주는 태그들입니다.
예) 구글 검색 시 표시 될 설명문, 사이트 제목, 카톡 공유 시 표시 될 이미지 등
우리는 그 중 og:image / og:title / og:description 을 크롤링 할 예정입니다.
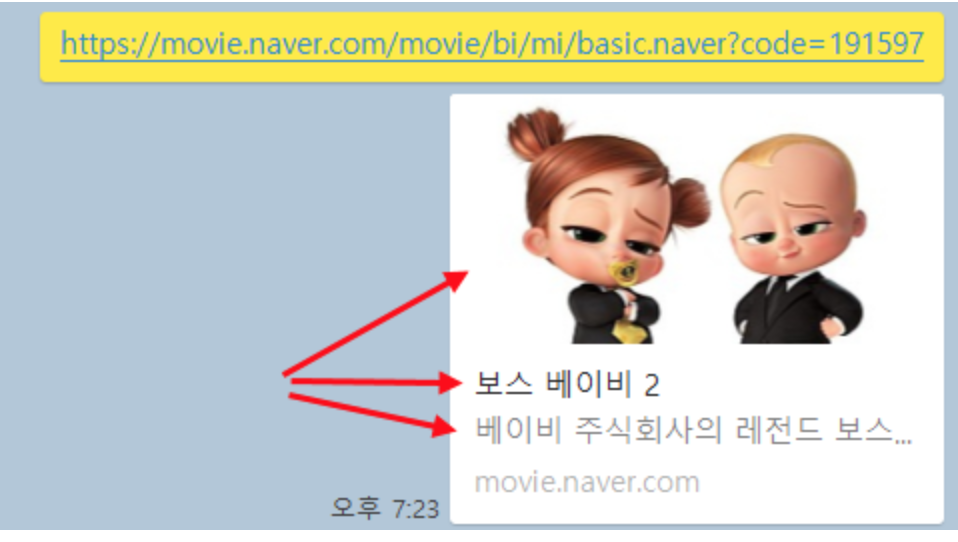
- meta 태그 스크래핑 하기
[크롤링 기본 코드]
import requests
from bs4 import BeautifulSoup
url = 'https://movie.naver.com/movie/bi/mi/basic.naver?code=191597'
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(url,headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 여기에 코딩을 해서 meta tag를 먼저 가져와보겠습니다.
[select_one을 이용해 meta tag를 먼저 가져와봅니다.]
og_image = soup.select_one('meta[property="og:image"]')
og_title = soup.select_one('meta[property="og:title"]')
og_description = soup.select_one('meta[property="og:description"]')
print(og_image)
print(og_title)
print(og_description)
[가져온 meta tag의 content를 가져와봅시다.]
image = og_image['content']
title = og_title['content']
description = og_description['content']
print(image)
print(title)
print(description)
[완성 코드]
import requests
from bs4 import BeautifulSoup
url = 'https://movie.naver.com/movie/bi/mi/basic.naver?code=191597'
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(url,headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
title = soup.select_one('meta[property="og:title"]')['content']
image = soup.select_one('meta[property="og:image"]')['content']
desc = soup.select_one('meta[property="og:description"]')['content']
print(title,image,desc)